

Introduction #
The authors of the COCO-Stuff 164k dataset discuss the significance of semantic classes, which can be categorized as either thing classes (objects with well-defined shapes, e.g., car, person) or stuff classes (amorphous background regions, e.g., grass, sky). They note that while much attention has been given to thing classes in classification and detection works, stuff classes have received less focus. However, they emphasize that stuff classes play a crucial role in understanding images, providing information about scene type, the likely presence and location of thing classes through contextual reasoning, physical attributes, material types, and geometric properties of the scene.
The COCO-Stuff 164k dataset supplements the COCO 2017 dataset with pixel-wise annotations for 91 stuff classes. It contains 172 classes in total: 80 thing, 91 stuff, and 1 class unlabeled. The 80 thing classes are the same as in COCO 2017. The 91 stuff classes are curated by an expert annotator. The class “unlabeled” is used in two situations: 1) if a label does not belong to any of the 171 predefined classes, or 2) if the annotator cannot infer the label of a pixel.
The hierarchy of labels:
Authors argue that stuff classes are essential as they constitute the majority of the visual environment, determine scene types, influence the understanding of thing classes’ locations, and contribute to depth ordering and relative positions of things.
Furthermore, they detail the protocol used for stuff labeling, emphasizing the efficiency of superpixel-based annotation and its accuracy compared to polygon-based annotation. They analyze the impact of boundary complexity on annotation time and highlight that superpixels offer a substantial improvement in annotation efficiency while maintaining accuracy.
In conclusion, the authors stress the importance of stuff classes in scene understanding, showcasing dataset’s value in augmenting the understanding of stuff-thing interactions in complex images. They also provide insights into the efficiency and accuracy of their annotation protocol.
 Homepage
Homepage Research Paper 1 (main)Research Paper 2
Research Paper 1 (main)Research Paper 2Summary #
COCO-Stuff 164k is a dataset for instance segmentation, semantic segmentation, and object detection tasks. It is applicable or relevant across various domains.
The dataset consists of 163957 images with 4691398 labeled objects belonging to 172 different classes including other, person, tree, and other: sky-other, wall-concrete, clothes, building-other, metal, grass, wall-other, pavement, furniture-other, table, road, window-other, textile-other, chair, car, dining table, light, plastic, fence, ceiling-other, dirt, bush, clouds, paper, plant-other, and 144 more.
Images in the COCO-Stuff 164k dataset have pixel-level instance segmentation and bounding box annotations. Due to the nature of the instance segmentation task, it can be automatically transformed into a semantic segmentation task (only one mask for every class). There are 40677 (25% of the total) unlabeled images (i.e. without annotations). There are 3 splits in the dataset: train2017 (118287 images), test2017 (40670 images), and val2017 (5000 images). Every image has a textual description in caption tag. Additionally, a hierarchy of the objects is contained within the category tag. Explore it in supervisely labeling tool. The dataset was released in 2018 by the University of Edinburgh, UK and Google AI Perception.

Explore #
COCO-Stuff 164k dataset has 163957 images. Click on one of the examples below or open "Explore" tool anytime you need to view dataset images with annotations. This tool has extended visualization capabilities like zoom, translation, objects table, custom filters and more. Hover the mouse over the images to hide or show annotations.




























































Class balance #
There are 172 annotation classes in the dataset. Find the general statistics and balances for every class in the table below. Click any row to preview images that have labels of the selected class. Sort by column to find the most rare or prevalent classes.

Class ㅤ | Images ㅤ | Objects ㅤ | Count on image average | Area on image average |
|---|---|---|---|---|
other➔ any | 122218 | 544881 | 4.46 | 57.96% |
person➔ any | 66808 | 634071 | 9.49 | 30.29% |
tree➔ any | 37991 | 128402 | 3.38 | 36.9% |
sky-other➔ any | 33119 | 100775 | 3.04 | 35.01% |
wall-concrete➔ any | 32833 | 114326 | 3.48 | 41.67% |
clothes➔ any | 28969 | 98317 | 3.39 | 16.26% |
building-other➔ any | 24030 | 87920 | 3.66 | 33.25% |
metal➔ any | 23979 | 81471 | 3.4 | 21.71% |
grass➔ any | 23509 | 91631 | 3.9 | 39.12% |
wall-other➔ any | 19736 | 64927 | 3.29 | 32.8% |
Images #
Explore every single image in the dataset with respect to the number of annotations of each class it has. Click a row to preview selected image. Sort by any column to find anomalies and edge cases. Use horizontal scroll if the table has many columns for a large number of classes in the dataset.
Class sizes #
The table below gives various size properties of objects for every class. Click a row to see the image with annotations of the selected class. Sort columns to find classes with the smallest or largest objects or understand the size differences between classes.
Class | Object count | Avg area | Max area | Min area | Min height | Min height | Max height | Max height | Avg height | Avg height | Min width | Min width | Max width | Max width |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
person any | 634071 | 5.39% | 100% | 0% | 1px | 0.21% | 640px | 100% | 122px | 25.8% | 1px | 0.16% | 640px | 100% |
other any | 544881 | 19.53% | 100% | 0.01% | 1px | 0.21% | 640px | 100% | 179px | 37.29% | 1px | 0.23% | 640px | 100% |
tree any | 128402 | 16.13% | 100% | 0.01% | 1px | 0.16% | 640px | 100% | 145px | 30.66% | 1px | 0.16% | 640px | 100% |
wall-concrete any | 114326 | 16.5% | 100% | 0% | 1px | 0.18% | 640px | 100% | 171px | 35.21% | 1px | 0.16% | 640px | 100% |
car any | 104272 | 1.98% | 100% | 0% | 2px | 0.31% | 640px | 100% | 45px | 9.76% | 2px | 0.31% | 640px | 100% |
sky-other any | 100775 | 18.72% | 100% | 0.01% | 1px | 0.21% | 640px | 100% | 140px | 29.33% | 1px | 0.16% | 640px | 100% |
clothes any | 98317 | 5.23% | 100% | 0% | 1px | 0.16% | 640px | 100% | 82px | 16.75% | 1px | 0.16% | 640px | 100% |
chair any | 93268 | 2.86% | 100% | 0% | 1px | 0.23% | 640px | 100% | 80px | 17.15% | 1px | 0.16% | 640px | 100% |
grass any | 91631 | 15.39% | 100% | 0% | 1px | 0.21% | 640px | 100% | 121px | 25.85% | 1px | 0.16% | 640px | 100% |
building-other any | 87920 | 13.01% | 100% | 0.01% | 2px | 0.31% | 640px | 100% | 133px | 27.58% | 1px | 0.16% | 640px | 100% |
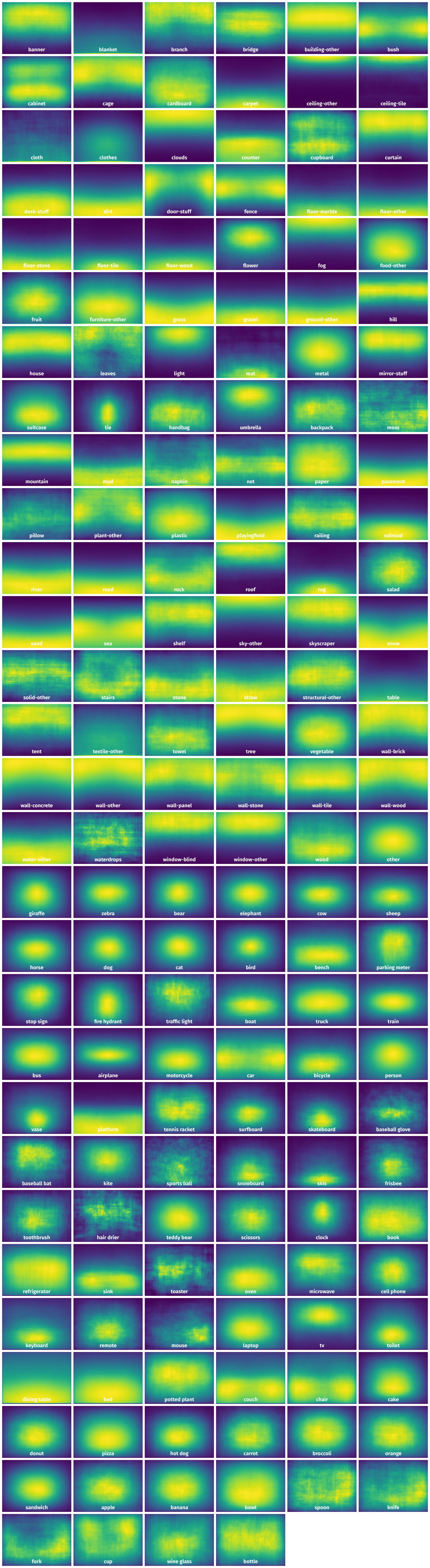
Spatial Heatmap #
The heatmaps below give the spatial distributions of all objects for every class. These visualizations provide insights into the most probable and rare object locations on the image. It helps analyze objects' placements in a dataset.
Objects #
Table contains all 98701 objects. Click a row to preview an image with annotations, and use search or pagination to navigate. Sort columns to find outliers in the dataset.
Object ID ㅤ | Class ㅤ | Image name click row to open | Image size height x width | Height ㅤ | Height ㅤ | Width ㅤ | Width ㅤ | Area ㅤ |
|---|---|---|---|---|---|---|---|---|
1➔ | clothes any | 000000084241.jpg | 396 x 640 | 25px | 6.31% | 18px | 2.81% | 0.08% |
2➔ | clothes any | 000000084241.jpg | 396 x 640 | 26px | 6.57% | 181px | 28.28% | 1.86% |
3➔ | food-other any | 000000084241.jpg | 396 x 640 | 34px | 8.59% | 47px | 7.34% | 0.27% |
4➔ | food-other any | 000000084241.jpg | 396 x 640 | 40px | 10.1% | 72px | 11.25% | 0.62% |
5➔ | food-other any | 000000084241.jpg | 396 x 640 | 75px | 18.94% | 85px | 13.28% | 1.45% |
6➔ | food-other any | 000000084241.jpg | 396 x 640 | 91px | 22.98% | 294px | 45.94% | 10.56% |
7➔ | furniture-other any | 000000084241.jpg | 396 x 640 | 233px | 58.84% | 312px | 48.75% | 7.03% |
8➔ | furniture-other any | 000000084241.jpg | 396 x 640 | 92px | 23.23% | 35px | 5.47% | 0.35% |
9➔ | furniture-other any | 000000084241.jpg | 396 x 640 | 77px | 19.44% | 44px | 6.88% | 0.83% |
10➔ | furniture-other any | 000000084241.jpg | 396 x 640 | 52px | 13.13% | 69px | 10.78% | 0.89% |
License #
COCO-Stuff is a derivative work of the COCO dataset. The authors of COCO do not in any form endorse this work. Different licenses apply:
- COCO images: Flickr Terms of use
- COCO annotations: Creative Commons Attribution 4.0 License
- COCO-Stuff annotations & code: Creative Commons Attribution 4.0 License
Citation #
If you make use of the COCO-Stuff 164k data, please cite the following reference:
@misc{caesar2018cocostuff,
title={COCO-Stuff: Thing and Stuff Classes in Context},
author={Holger Caesar and Jasper Uijlings and Vittorio Ferrari},
year={2018},
eprint={1612.03716},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
If you are happy with Dataset Ninja and use provided visualizations and tools in your work, please cite us:
@misc{ visualization-tools-for-cocostuff164k-dataset,
title = { Visualization Tools for COCO-Stuff 164k Dataset },
type = { Computer Vision Tools },
author = { Dataset Ninja },
howpublished = { \url{ https://datasetninja.com/cocostuff164k } },
url = { https://datasetninja.com/cocostuff164k },
journal = { Dataset Ninja },
publisher = { Dataset Ninja },
year = { 2026 },
month = { jul },
note = { visited on 2026-07-19 },
}Download #
Dataset COCO-Stuff 164k can be downloaded in Supervisely format:
As an alternative, it can be downloaded with dataset-tools package:
pip install --upgrade dataset-tools
… using following python code:
import dataset_tools as dtools
dtools.download(dataset='COCO-Stuff 164k', dst_dir='~/dataset-ninja/')
Make sure not to overlook the python code example available on the Supervisely Developer Portal. It will give you a clear idea of how to effortlessly work with the downloaded dataset.
The data in original format can be downloaded here:
- COCO 2017 train images (118K images) [18GB]
- COCO 2017 val images (5K images) [1GB]
- Stuff+thing PNG-style annotations on COCO 2017 trainval [669MB]
- Stuff-only COCO-style annotations on COCO 2017 trainval [554MB]
- Thing-only COCO-style annotations on COCO 2017 trainval [241MB]
- Indices, names, previews and descriptions of the classes in COCO-Stuff
- Machine readable version of the label list
Disclaimer #
Our gal from the legal dep told us we need to post this:
Dataset Ninja provides visualizations and statistics for some datasets that can be found online and can be downloaded by general audience. Dataset Ninja is not a dataset hosting platform and can only be used for informational purposes. The platform does not claim any rights for the original content, including images, videos, annotations and descriptions. Joint publishing is prohibited.
You take full responsibility when you use datasets presented at Dataset Ninja, as well as other information, including visualizations and statistics we provide. You are in charge of compliance with any dataset license and all other permissions. You are required to navigate datasets homepage and make sure that you can use it. In case of any questions, get in touch with us at hello@datasetninja.com.